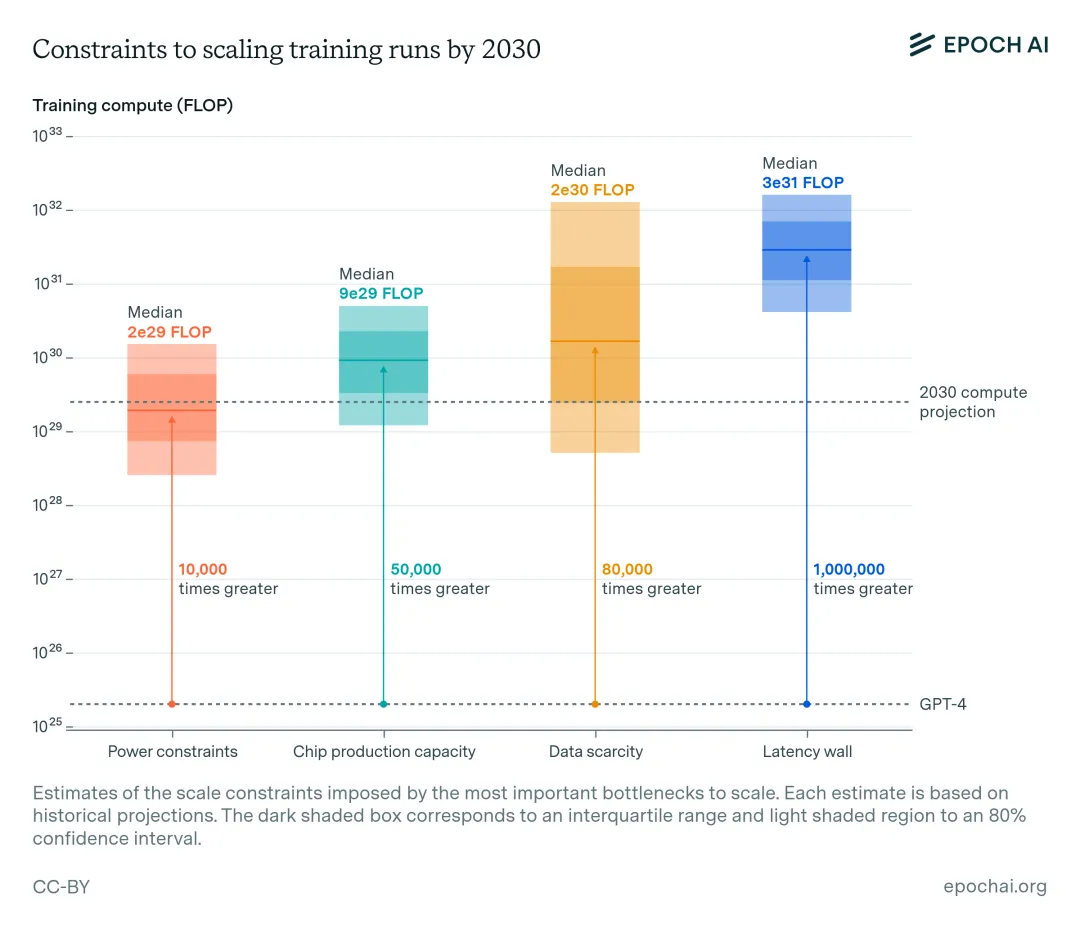
2030年,Scaling Law会到达极限吗?GPT-6能出来吗?
2030年,Scaling Law会到达极限吗?GPT-6能出来吗?9 月 2 日,马斯克发文称,其人工智能公司 xAI 的团队上线了一台被称为「Colossus」的训练集群,总共有 100000 个英伟达的 H100 GPU。
来自主题: AI资讯
6672 点击 2024-09-08 10:50
 搜索
搜索
9 月 2 日,马斯克发文称,其人工智能公司 xAI 的团队上线了一台被称为「Colossus」的训练集群,总共有 100000 个英伟达的 H100 GPU。

沿着 Scaling Law、卷模型性能,可能会走到「死胡同」。

沿着 Scaling Law、卷模型性能,可能会走到「死胡同」。 谁在影响、定义我们的时代?他们做了什么,如何思考?对话关键人物,记录历史底稿。 我们被倡导要想明白自己的目标是什么、并做出计划。然而,两位人工智能研究者却认为,这只适用于普通的小愿望。

近年来,Transformer等预训练大模型在语言理解及生成等领域表现出色,大模型背后的Scaling Law(规模定律)进一步揭示了模型性能与数据量、算力之间的关系,强化了数据在提升AI表现中的关键作用。

AnyGraph聚焦于解决图数据的核心难题,跨越多种场景、特征和数据集进行预训练。其采用混合专家模型和特征统一方法处理结构和特征异质性,通过轻量化路由机制和高效设计提升快速适应能力,且在泛化能力上符合Scaling Law。
从几周前 Sam Altman 在 X 上发布草莓照片开始,整个行业都在期待 OpenAI 发布新模型。根据 The information 的报道,Strawberry 就是之前的 Q-star,其合成数据的方法会大幅提升 LLM 的智能推理能力,尤其体现在数学解题、解字谜、代码生成等复杂推理任务。这个方法也会用在 GPT 系列的提升上,帮助 OpenAI 新一代 Orion。

本文的主要作者来自香港大学的数据智能实验室 (Data Intelligence Lab@HKU)。
最近,又一款国产 AI 神器吸引了众网友和圈内研究人员的关注!它就是全新的图像和视频生成控制工具 —— ControlNeXt,由思谋科技创始人、港科大讲座教授贾佳亚团队开发。

为了实现算力层面的提升和追赶,国内有大量的厂商和从业者在各个产业链环节努力。但面对中短期内架构、制程、产能、出口禁令等多方面的制约,我们认为从芯片层面实现单点的突破依旧是非常困难且不足的。
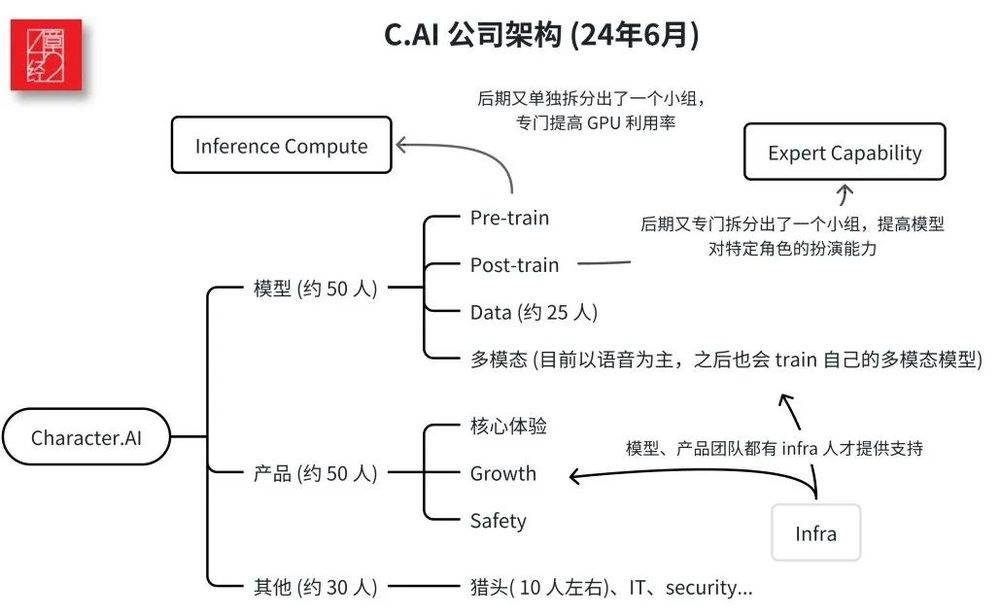
C.AI被收购是因市场和创始人选择,Scaling Law加剧了竞争。 • C.AI选择做模型公司以获得高估值。 • Google收购C.AI以应对AI市场竞争。 • Scaling Law使大模型公司竞争更激烈。